写了个电影搜索引擎 – 十万电影资源分享哦
by Xiaoxia
at 2012-10-12 02:44:47
original http://www.udpwork.com/item/8231.html
好吧,做了一个很疯狂的东西!http://movie.readself.com/
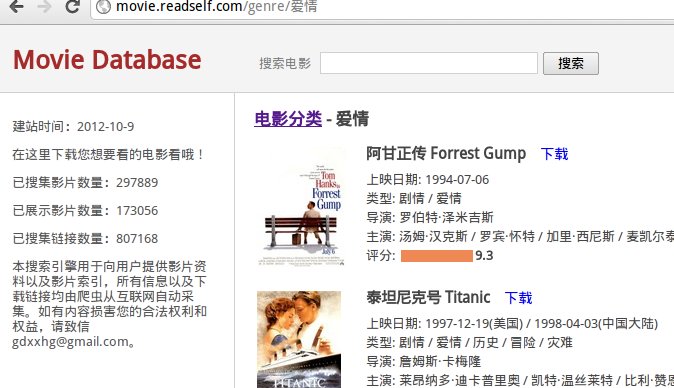
平常我想要看电影的时候,总是需要在Google或者Baidu里搜索很长时间才能找到一个下载链接。
比如说,我想看《黑天鹅》,我就去Google里搜索:
ext:mkv Black Swan
然后就搜出种子或者下载链接了。那么这一个过程,是否可以简化呢?是否可以预先搜集好每个影片的下载链接,然后存到数据库里,方便我想看电影的时候直接调出来下载呢?所以就这样萌生了写个爬虫的想法!最初还是听说荣哥写了一个爬虫放在学校的服务器爬了3个小时,就把100万首音乐资料全部下载了。我后来本想跟随荣哥的足迹的,但突然觉得电影对于我来说比音乐更重要些。预祝荣哥顺利踏上去谷歌山景城总部的愉快旅程![]()
结合我之前做博客搜索引擎的经验,这次做一个电影资源搜索引擎吧!除了自己使用之外,还可以推荐给身边的各位朋友使用。私底下分享即可!

为了搜集这些电影资料,写了n多个爬虫,分别干不同的事情,整合了几个站点的资源。幸好教育网网速还行,每次基本上都可以用几个小时就爬完我需要的影片信息。不同站点的资源的整合,也写了不少程序来智能匹配。比如说,我现在有100多万的电影下载地址或者种子,我怎么跟我的影片信息库关联起来呢?按照我以往做文本分析的经验,通过计算链接和影片信息之间的联系程度,取关联程度最高的一个进行匹配。尽管如此,我发现还是有5%左右的影片的下载地址是错误的,比如2012。因为这个根据这个数字直接匹配2012年的片子了……
在下载链接的列表里,我做了一个简单的排名,把尽量与影片关联程度最高的,以及高清和速度好的链接排在前面。通过这样保证第一个下载链接的可靠性!
这次搜集电影信息的存储没有使用MySQL了,而是使用了MongoDB,性能很好,CPU占用少,用起来很方便,一点也不像MySQL那么繁琐啊。不过在吃光了内存之后,写入硬盘的时候,速度就太坑爹了,硬盘灯常亮啊,Firefox直接卡死,开了100个线程,CPU和网络利用率还是很低!因为爬虫一开始都把网页内容直接塞到MongoDB里,所以爬完后,信息内容的大小超过30GB了(包括小尺寸的海报)。写了几个脚本把影片信息提取出来,去掉了冗余数据,最后剩下10GB,上传到readself.com的VPS(内存512M,硬盘20G)上,跑起来妥妥的,搜索速度也很快!!!
分享地址:http://movie.readself.com/
看吧,小虾过了一段时间又给大家带来好玩的东西了!我本人在Linux下使用KTorrent,在Windows使用μTorrent,下载速度都很给力!用迅雷也可以下载磁力链接的文件。
给朋友们使用一下,觉得好,请评论啊![]()
<div style="margin-top:8px;padding:6px 0;border-top:1px solid #3cf">
<div style="text-align:center;margin:16px 0;padding:6px;border:0px dashed #999;font-family:arial;font-size:26px;font-weight:bold">
<a href="http://www.udpwork.com/item/8231.html#review_form" title="不喜欢" style="text-decoration:none">
<img src="http://www.udpwork.com//images/thumb_down24.gif" alt="">
<span style="color:#f33">0</span>
</a>
<a href="http://www.udpwork.com/item/8231.html#review_form" title="喜欢" style="text-decoration:none">
<img src="http://www.udpwork.com//images/thumb_up24.gif" alt="">
<span style="color:#3c3">36</span>
</a>